B2B 시스템을 운영하는 개발자라면 누구나 한 번쯤 새벽 배포를 경험해 보았을 것입니다. 고객사 업무 시간 외에만 업데이트가 가능한 구조에서 무중단 배포 없이는 야근이 일상이 됩니다. 본 시리즈는 10년차 Spring Boot 개발자가 실제 운영 시스템에 소프트 로드밸런싱을 도입해 야근 문화를 끊어낸 실전 구축기를 다룹니다.
이 글(1편)에서는 Nginx와 HAProxy 두 가지를 모두 운영한 끝에 Nginx 단독으로 정착한 의사결정 과정과 실제 운영에 사용하는 Nginx 설정 파일을 공개합니다. 후속 편에서는 세션 클러스터링과 JWT 인증 전환까지 이어집니다.
B2B 운영 환경의 배포 딜레마
B2B 서비스는 일반 컨슈머 서비스와 배포 제약이 완전히 다릅니다. 고객사가 업무 시간에 시스템을 점유하기 때문에 모든 배포 작업이 야간 또는 새벽 시간대로 밀려납니다. 저희 팀도 초기에는 거의 모든 릴리즈를 오후 11시 이후에 수행했고, 핫픽스 한 건만 발생해도 새벽 3시까지 모니터링하는 일이 잦았습니다.
이 구조가 문제였던 진짜 이유는 단순 야근이 아닙니다. 배포 실패 시 롤백 시간이 곧 장애 시간이 되고, 다음 날 고객사 업무 시작 전까지 복구하지 못하면 SLA 위반으로 직결됩니다. 개발자가 피곤한 상태에서 새벽에 결정하는 롤백은 또 다른 장애를 부르기도 했습니다.
해결책은 명확했습니다. 업무 시간 중에도 사용자가 인지하지 못하는 형태로 배포할 수 있는 구조, 즉 무중단 배포 아키텍처가 필요했습니다.
왜 소프트 로드밸런싱이었는가
무중단 배포를 위한 로드밸런서 선택지는 크게 세 가지입니다.
| 구분 | 하드웨어 LB (F5 등) | 클라우드 LB (ALB/ELB) | 소프트 LB (Nginx/HAProxy) |
|---|---|---|---|
| 도입 비용 | 매우 높음 | 사용량 기반 | 무료(오픈소스) |
| 세부 제어 | 제한적 | 콘솔 위주 | 설정 파일로 완전 제어 |
| 학습 곡선 | 낮음 | 낮음 | 중간 |
| 온프레미스 | 가능 | 불가 | 가능 |
저희 환경은 고객사 IDC에 설치되는 온프레미스 구조가 많았기 때문에, 클라우드 LB는 사용할 수 없었습니다. 결국 비용·이식성·제어권 측면에서 오픈소스 소프트 로드밸런서가 정답이었고, 시장에서 가장 검증된 두 후보가 HAProxy와 Nginx였습니다.
어느 한쪽을 단번에 고르지 못한 이유는 두 제품의 강점이 너무 명확하게 갈렸기 때문입니다. HAProxy는 L4/L7 트래픽 라우팅과 헬스체크가 견고하고, Nginx는 정적 자원 서빙·HTTPS 종단·리버스 프록시에 강합니다. 결국 두 가지를 모두 운영해 보면서 우리 환경에 맞는 한쪽으로 수렴시키기로 했습니다.
HAProxy를 먼저 도입한 이유와 운영 경험
처음 도입한 것은 HAProxy였습니다. 이유는 단순했습니다. 로드밸런서의 정체성에 가장 충실한 도구였기 때문입니다. HAProxy는 처음부터 부하 분산만을 위해 설계된 도구이고, 통계 화면(stats), admin socket 기반 동적 제어, 세밀한 헬스체크 옵션 등 운영자가 원하는 모든 제어 손잡이가 처음부터 준비되어 있습니다.
도입 직후의 만족도는 매우 높았습니다. HAProxy의 admin socket을 통해 재시작 없이도 가중치를 실시간 변경할 수 있었고, /actuator/health 기반 애플리케이션 레벨 헬스체크로 톰캣 인스턴스의 실제 상태를 정확히 추적했습니다. 새 인스턴스에 가중치를 20→50→100으로 점진 적용해 JIT 워밍업 시간까지 확보하는 카나리아 형태도 자연스러웠습니다.
그러나 1년 정도 운영하면서 두 가지 불편함이 드러났습니다.
첫째, 버전 업데이트 주기가 느렸습니다. 보안 패치는 백포팅되어 오지만, 새로운 프로토콜 지원이나 운영 편의 기능은 한 박자씩 늦었습니다. HTTP/2와 TLS 1.3 같은 메이저 변화가 있을 때 HAProxy 진영의 안정 LTS에 반영되기까지 시간이 필요했고, 그 사이에 우리는 보수적 운영을 강요받았습니다.
둘째, 정적 자원 서빙·SSL 종단을 결국 별도 도구로 처리해야 했습니다. HAProxy도 SSL 종단은 가능하지만 정적 파일 캐싱·gzip·이미지 압축 같은 영역은 본업이 아닙니다. 결국 앞단에 별도의 웹 서버를 두는 구성이 되어 운영 컴포넌트 수가 늘었습니다.
Nginx로 전환을 결심한 결정적 이유 업데이트 빈도
Nginx 진영의 강점은 운영을 시작하자마자 체감했습니다. 가장 결정적이었던 것은 mainline 라인의 업데이트 주기입니다. Nginx mainline은 보통 1~2개월 간격으로 신규 기능과 보안 패치가 함께 릴리즈됩니다. 반면 HAProxy 안정 라인은 같은 기간 안에 같은 양의 변화를 반영하기 어렵습니다.
특히 HTTP/2, HTTP/3(QUIC), TLS 1.3, OCSP Stapling, brotli 압축 같은 최신 프로토콜과 보안 옵션의 채택 속도가 Nginx 쪽이 훨씬 빨랐습니다. B2B 고객사 보안 감사에서 “최신 TLS만 허용하라”는 요구가 자주 들어왔는데, Nginx에서는 한 줄 수정으로 대응이 끝났습니다.
| 비교 항목 | HAProxy | Nginx (mainline) |
|---|---|---|
| 신규 버전 주기 | 분기~반기 | 1~2개월 |
| HTTP/2 도입 시점 | 1.8 (2017) | 1.9.5 (2015) |
| HTTP/3·QUIC 지원 | 2.6+ (실험) | 1.25+ 정식 |
| TLS 1.3 안정화 | 2.0+ | 1.13+ (선반영) |
| 정적 자원·캐싱 | 약함 | 매우 강함 |
| 부하 분산 옵션 | 매우 풍부 | 충분(상용판 더 풍부) |
| 동적 가중치 변경 | admin socket | OSS는 reload, NGINX Plus는 API |
결정적 한 줄로 정리하면 다음과 같습니다. HAProxy의 강점이었던 부하 분산 기능을 Nginx도 충분히 제공하는 반면, Nginx의 강점인 최신성과 정적 자원 처리는 HAProxy가 따라잡기 힘들었습니다. 그렇다면 운영 도구는 하나로 줄이는 것이 안정성에 더 기여합니다.
오해 없이 강조하자면 HAProxy가 나쁜 도구라는 뜻은 아닙니다. 초대형 트래픽이나 L4 정밀 제어가 필요한 환경에서는 여전히 HAProxy가 표준입니다. 다만 우리 규모(인스턴스 2~4대)와 우리 요구사항(최신 TLS·HTTP/2·정적 자원 일체화)에서는 Nginx 한 가지가 운영 만족도가 더 높았습니다.
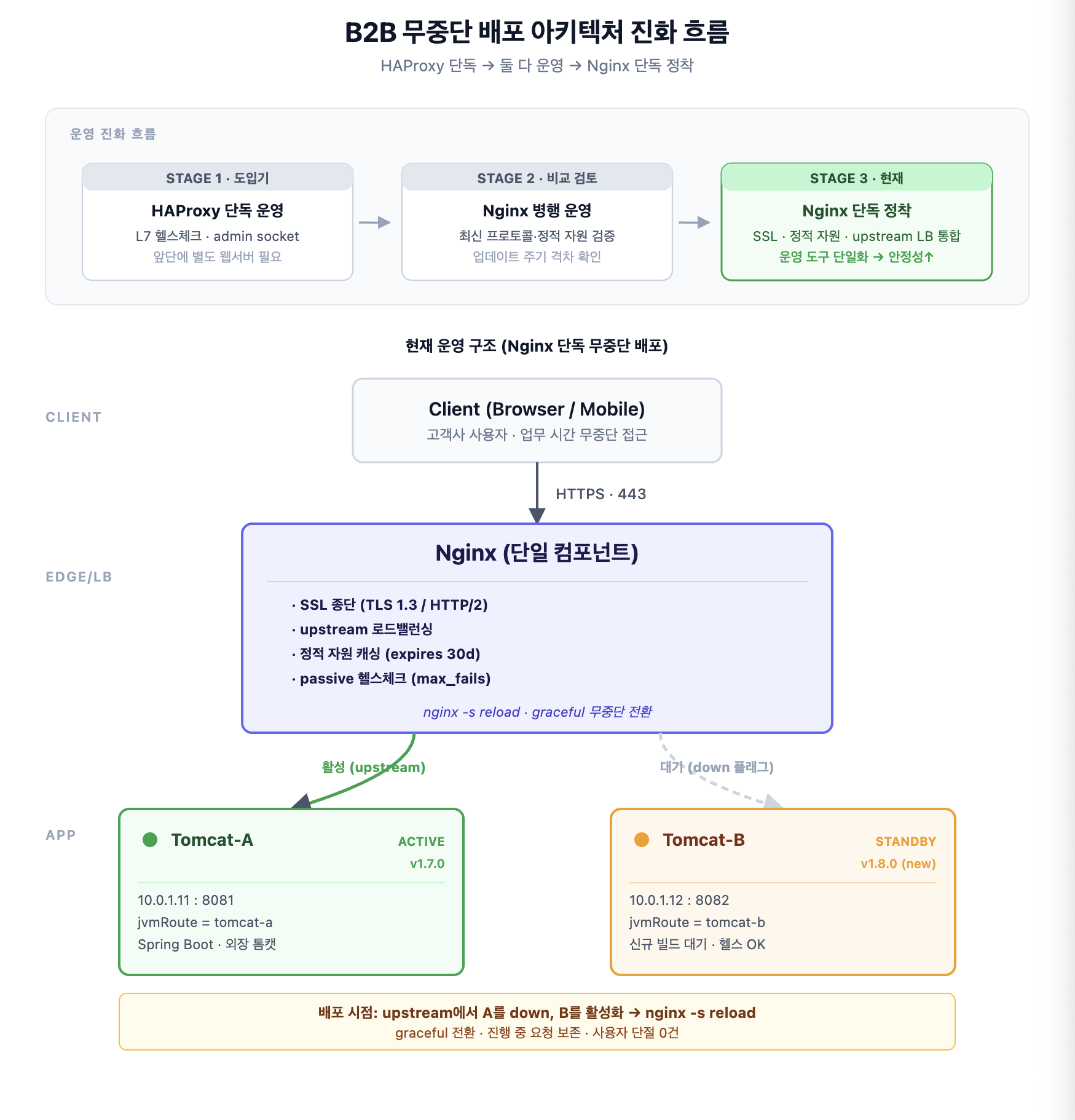
Nginx 단독 무중단 배포 구조
최종 정착한 구조는 다음과 같습니다. Nginx가 SSL 종단·정적 자원·로드밸런싱·헬스체크를 모두 담당하고, 그 뒤로 외장 톰캣 두 대(Blue/Green)가 위치합니다.
[Client]
↓ HTTPS
[Nginx] ← SSL 종단 · 정적 자원 · upstream LB
↓ HTTP
[Tomcat-A] [Tomcat-B] ← 외장 톰캣 2대 (Blue/Green)
↓
[DB / Redis]
핵심은 Tomcat-A와 Tomcat-B를 동시에 띄워두고, Nginx의 upstream 블록에서 한쪽을 down으로 표시한 뒤 nginx -s reload로 트래픽을 전환하는 방식입니다. reload는 graceful 동작이라 진행 중인 요청을 끊지 않고 새 워커가 새 설정을 적용하므로 사용자 입장에서는 단절이 없습니다.
Nginx 설정 풀 공개 upstream과 헬스체크
실제 운영의 nginx.conf 핵심 블록입니다.
# /etc/nginx/conf.d/app.conf
upstream app_backend {
# 활성 인스턴스
server 10.0.1.11:8081 max_fails=2 fail_timeout=10s;
# 비활성 인스턴스 (배포 대기/신규 빌드)
server 10.0.1.12:8082 max_fails=2 fail_timeout=10s down;
keepalive 32;
}
server {
listen 443 ssl http2;
server_name app.example.com;
ssl_certificate /etc/nginx/ssl/fullchain.pem;
ssl_certificate_key /etc/nginx/ssl/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 1d;
# 정적 자원 캐싱
location ~* \.(js|css|png|jpg|jpeg|gif|ico|woff2?)$ {
expires 30d;
add_header Cache-Control "public, immutable";
access_log off;
}
# 동적 요청은 upstream으로
location / {
proxy_pass http://app_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 5s;
proxy_read_timeout 60s;
# 백엔드 장애 시 다른 인스턴스로 자동 재시도
proxy_next_upstream error timeout http_502 http_503 http_504;
proxy_next_upstream_tries 2;
}
# 모든 백엔드 다운 시 점검 페이지
error_page 502 503 504 /maintenance.html;
location = /maintenance.html {
root /var/www/maintenance;
internal;
}
}
server {
listen 80;
server_name app.example.com;
return 301 https://$server_name$request_uri;
}
세 가지 포인트를 짚어 두겠습니다.
첫째, down은 해당 서버를 라우팅 대상에서 제외하는 플래그입니다. 배포 시 신규 빌드를 올린 인스턴스 쪽에서 이 플래그를 제거해 트래픽을 받게 합니다. 둘째, max_fails/fail_timeout은 수동 헬스체크(passive) 입니다. 오픈소스 Nginx는 능동 헬스체크가 없지만, 별도 스크립트(curl /actuator/health)와 결합하면 실효적인 제어가 가능합니다. 셋째, proxy_next_upstream은 백엔드 한 대가 502/503/504로 응답할 때 자동으로 다른 인스턴스로 재시도합니다. 사용자가 5xx를 보기 전에 LB 레벨에서 흡수합니다.
Nginx 기반 Blue/Green 배포 스크립트
운영에서 사용하는 배포 스크립트의 흐름은 다음과 같습니다.
#!/bin/bash
set -euo pipefail
NGINX_CONF="/etc/nginx/conf.d/app.conf"
NEW_TARGET="${1:-tomcat-b}" # 배포할 대상
# 1) 비활성 인스턴스에 신규 빌드 배포 (별도 ansible/scp 단계 생략)
deploy_app "$NEW_TARGET"
# 2) 헬스체크 대기 (최대 90초)
for i in $(seq 1 30); do
if curl -sf "http://${NEW_TARGET}:8082/actuator/health" | grep -q '"status":"UP"'; then
echo "Health OK"; break
fi
sleep 3
done
# 3) 단계적 트래픽 전환 (down 플래그 토글)
# A를 down 처리하고 B를 활성화
sed -i 's|server 10.0.1.12:8082 .*|server 10.0.1.12:8082 max_fails=2 fail_timeout=10s;|' "$NGINX_CONF"
sed -i 's|server 10.0.1.11:8081 .*|server 10.0.1.11:8081 max_fails=2 fail_timeout=10s down;|' "$NGINX_CONF"
# 4) graceful reload (진행 중인 요청을 끊지 않음)
nginx -t && nginx -s reload
# 5) 5분 모니터링 후 구버전 인스턴스 교체
sleep 300
deploy_app "tomcat-a"
핵심은 nginx -s reload가 graceful이라는 점입니다. 기존 워커 프로세스는 진행 중인 요청을 모두 처리한 후 종료되고, 새 워커가 새 설정으로 시작합니다. 사용자 입장에서는 단 1건의 5xx도 발생하지 않습니다.
nginx -t로 사전 문법 검증을 거치는 것도 필수입니다. 잘못된 설정으로 reload하면 워커 시작 자체가 실패할 수 있습니다.
HAProxy 시절 사용했던 참고 설정
같은 단계를 HAProxy로 운영했을 때의 설정도 참고용으로 남깁니다. HAProxy를 선택해야 하는 환경에 있는 분들이 있을 수 있으니, 동일한 의사결정 흐름을 HAProxy로 그대로 옮긴 형태입니다.
frontend web_front
bind *:8080
default_backend tomcat_cluster
backend tomcat_cluster
balance roundrobin
option httpchk GET /actuator/health
http-check expect status 200
default-server inter 3s fall 2 rise 2
server tomcat-a 10.0.1.11:8081 check weight 100
server tomcat-b 10.0.1.12:8082 check weight 0
배포 시 admin socket으로 가중치를 바꾸는 명령은 다음과 같습니다.
echo "set weight tomcat_cluster/tomcat-a 0" | socat stdio /var/lib/haproxy/stats
echo "set weight tomcat_cluster/tomcat-b 100" | socat stdio /var/lib/haproxy/stats
이 구조 자체에는 문제가 없습니다. 단, 앞단에 정적 자원·SSL 종단을 위한 Nginx가 별도로 필요하다는 점, 그리고 최신 프로토콜 채택 속도에서 차이가 났다는 점이 우리 의사결정의 분기점이었습니다.
도입 후 변화
소프트 로드밸런싱 도입 이후 야간 배포 빈도는 월 12회에서 월 1~2회로 감소했습니다. 정기 릴리즈는 평일 오전 10시에 수행하게 되었고, 핫픽스도 점심시간에 안전하게 배포할 수 있게 되었습니다. 운영 컴포넌트가 Nginx 한 가지로 정착한 뒤로는 설정 파일 관리·버전 업그레이드·보안 패치 적용의 부담도 절반 이하로 줄었습니다.
하지만 새로운 문제가 등장했습니다. 세션 기반 인증을 사용 중인데 트래픽이 다른 톰캣으로 넘어가면 사용자가 로그아웃되는 현상이 발생한 것입니다. 이 문제를 해결하기 위해 톰캣 클러스터링을 도입했고, 그 과정은 “2편 외장 톰캣 세션 클러스터링 도입기에서 자세히 다룹니다. 결국 세션 클러스터의 한계까지 만나게 되었는데, 그 다음 여정은 3편 “Spring Security JWT 전환기“에서 이어집니다.
자주 묻는 질문 (FAQ)
Q1. Nginx 오픈소스에는 능동 헬스체크가 없지 않나요?
맞습니다. 오픈소스 Nginx는 max_fails/fail_timeout 기반 수동 헬스체크만 제공합니다. 대신 배포 스크립트에서 curl /actuator/health로 사전 검증한 뒤 nginx -s reload로 전환하는 패턴을 사용하면 실용상 동일한 효과를 얻을 수 있습니다. 능동 헬스체크가 꼭 필요하다면 NGINX Plus 또는 nginx_upstream_check_module 같은 서드파티 모듈을 검토하실 수 있습니다.
Q2. 처음부터 Nginx로 시작했으면 더 좋지 않았나요?
결과론적으로는 그렇습니다. 다만 HAProxy를 직접 운영해본 경험이 있었기 때문에 Nginx 설정의 트레이드오프를 정확히 판단할 수 있었습니다. 가중치 조정의 즉시성, 통계 화면의 풍부함 등은 HAProxy가 분명히 강점이라는 사실을 체감했고, 그럼에도 운영 도구 단일화의 장점이 더 크다는 판단을 할 수 있었습니다.
Q3. 무중단 배포 시 DB 스키마 변경은 어떻게 처리하나요?
Expand-Migrate-Contract 패턴을 사용합니다. 컬럼 추가는 nullable로 먼저 추가하고, 신·구 버전이 모두 동작하는 호환 코드를 거쳐, 마지막에 불필요한 컬럼을 제거합니다. 무중단 배포의 진짜 난이도는 LB 설정보다 DB 마이그레이션 전략에 있습니다.
Q4. nginx -s reload 도중 요청이 끊기지 않는 게 정말 보장되나요?
기존 워커 프로세스는 처리 중이던 요청을 모두 완료한 뒤에야 종료됩니다. 새 요청은 새 워커가 받기 시작하므로 사용자 입장에서는 단절이 없습니다. 단, 장시간 실행되는 WebSocket 연결은 graceful timeout(worker_shutdown_timeout)에 도달하면 강제 종료될 수 있으니, 해당 워크로드가 있는 환경에서는 별도 정책이 필요합니다.
Q5. 클라우드 환경이면 ALB만 써도 충분하지 않나요?
충분합니다. 온프레미스·멀티클라우드 환경이거나 L7 요청 라우팅을 세밀하게 제어해야 하는 환경에서만 소프트 LB가 의미가 있습니다. 저희가 Nginx를 선택한 가장 큰 이유는 고객사 IDC에 동일한 아키텍처를 일관되게 설치할 수 있다는 점이었습니다.
마무리
10년차 백엔드 개발자로서 가장 만족스러웠던 인프라 개선 중 하나가 바로 이 무중단 배포 구조의 도입이었습니다. 더 만족스러웠던 것은 두 가지 도구를 직접 운영해보고 우리 환경에 맞는 한쪽을 골랐다는 점이었습니다. 도구 선택은 인터넷의 의견이 아니라 자기 환경의 트레이드오프가 결정합니다. 우리 환경에서는 운영 컴포넌트 수, 최신 프로토콜 채택 속도, 정적 자원 처리가 결정적 변수였고, 그 답이 Nginx였을 뿐입니다.
다만 이 구조는 시작에 불과했습니다. 세션 기반 인증과 무중단 배포는 본질적으로 충돌하는 측면이 있고, 그 첫 충돌을 해결한 것이 다음 편의 톰캣 세션 클러스터링입니다. 시리즈를 통해 무중단 배포·세션 공유·JWT 전환으로 이어지는 실전 여정을 끝까지 따라와 주시면, 동일한 상황을 마주한 팀에서 단계별로 어떤 결정을 해야 하는지 명확한 지도를 얻으실 수 있을 것입니다.
핵심 요약
- B2B 야근의 해결책은 소프트 로드밸런싱 기반 무중단 배포, 후보는 Nginx와 HAProxy
- HAProxy를 먼저 도입했지만 업데이트 주기·최신 프로토콜 채택 속도에서 Nginx mainline이 우세
- 운영 도구를 하나로 줄이는 것의 안정성 이득이 더 크다고 판단해 Nginx 단독으로 정착
- 실제 무중단 배포 핵심은 upstream
down토글 +nginx -s reloadgraceful 동작- HAProxy도 좋은 도구이며, L4 정밀 제어·초대형 트래픽 환경에서는 여전히 표준
- 본 시리즈 2편에서는 세션 클러스터링, 3편에서는 JWT 전환을 다룸
“무중단 배포 Nginx vs HAProxy 둘 다 써본 후기”에 대한 2개의 생각